Real-time Dashboard App with Kafka, Beam, Dataflow, BigQuery, Data Studio, and Streamlit
What does it take to create a real-time dashboard app to prepare and display aggregated streaming data? This article explores a sample application that leverages powerful frameworks, cloud services, and infrastructure to achieve this with little effort.
Application
Aggregate and display top Twitter hashtags within a specific time window in real-time.
In a nutshell, the application receives data from Twitter Filtered Stream API, pushes to Kafka topics, and aggregates with Dataflow Beam app to be consumed by Streamlit powered UI.
High-Level Architecture
In this application, we are using Twitter Filtered Stream API as the data source. It is easy to set up and a great way to simulate real-world applications. Concepts in this article also apply to other data sources.
Twitter filtered stream API uses ‘track’ specified by the consumer to send filtered ‘Status’ events. One of the design decisions we made early on is to have a per ‘track’ instance of data pipeline instead of a single instance handling multiple tracks. Some of the driving factors are:
- Each track’s output data should be queried independently. Emitting the final data to different locations can simplify the logic for the consumption layer.
- Each track's data rate can be very different for each track and might require different scaling ratios. Therefore separate topics and pipeline jobs make sense.
- Provisioning and un-provisioning new track processing should be as isolated as possible not to affect other tracks.
This approach's disadvantage is provisioning a new track pipeline requires a few control plane operations, which can be slow. Depending on the requirements and considering the trade-offs, either option or a hybrid solution can be chosen. For this architecture, we picked the isolated option.
Then, for a single instance, the data pipeline for a track query and processing includes:
- Kafka cluster in GCP
- Java app that pushes data from Tweeter API to Kafka
- Dataflow Scala Beam app with Kafka.IO stream processing and aggregation, emitting output to Google Storage bucket and BigQuery.
- Data visualization and analytics with Google Data Studio
- Presentation with Streamlit app


Components
Next, we will look into individual components.
Generating the Data
We used saurzcode/twitter-stream as the base app to retrieve Status events and push them to Kafka topic. The changes needed to deploy to Google App Engine are here.
Kafka Node in GCP
Single node “click to deploy GCP Kafka” cluster for development. Easy to set up and configure. One thing to note, for Dataflow to read from this cluster, we need to:
- Promote ephemeral external IP address
- Setup a firewall rule to allow traffic to the port broker is listening on. Before opening the Kafka port, we would add authentication like SASL to the cluster in a production environment.
Realtime Processing with Beam App and Dataflow
Apache Beam is the answer if we are looking for a programming model where we write once to use on different platforms. With Beam, we can test the data processing pipeline locally with the direct runner, then move it to Spark, Flink or Dataflow seamlessly. All supported runners and their capabilities are listed here. For this application, we will use the Dataflow runner provided by GCP.
As shown below, the Scala beam application uses Kafka.IO to read raw events from the topic we set up and populated earlier per track query. Instead of using the default timestamp policy to extract event time from Status, a custom policy is configured. Then, the processing pipeline extracts hashtags from the input elements, applies windowing to aggregate total count per hashtag over a 2mins sliding window of 20sec (note these are configurable times). We use a custom triggering to handle late arrivals, which is accumulated into the pane’s calculation within the allowed time of 5mins and discarded beyond that. Beam documentation has more details on watermark and late data and triggers. The windowed output is written to both the GCS bucket and BigQuery.
The above pipeline’s representation with the steps and branching in Dataflow UI is shown below.

Dataflow console provides detailed insights into the pipeline. For example, we can monitor watermark and processing metrics.
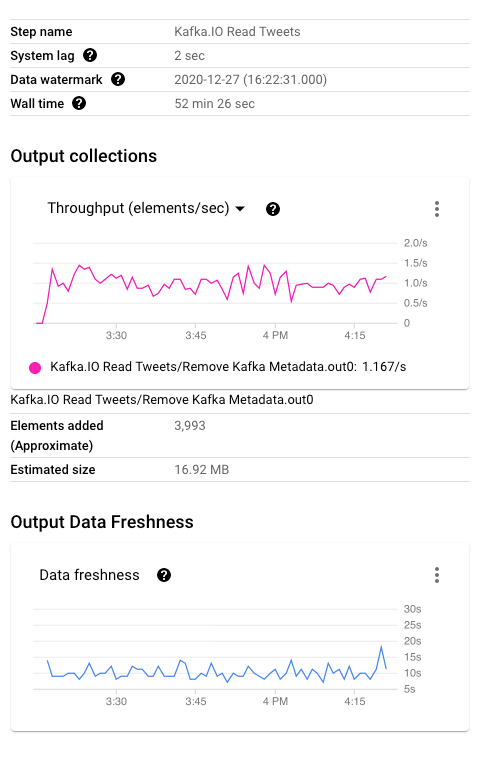

Output
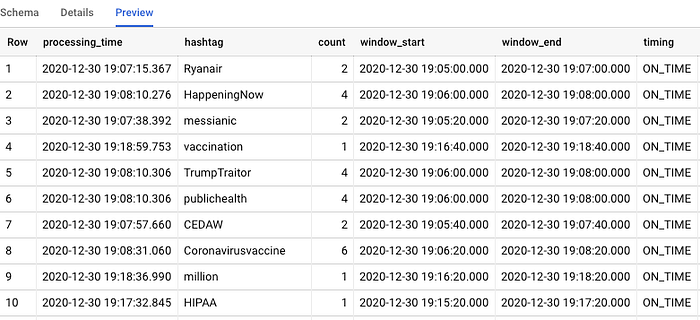
- BigQuery: Beam app will emit each output with window and timing information to BigQuery. Later we will use this to visualize and gain insights in Data Studio. Note that window information and pane timing is also emitted for debugging.
- Google Storage bucket: Beam app will also emit windowed output to the GCS bucket to be consumed Streamlit dashboard app.
Consumption
- Data Studio: Using powerful visualization features of Data studio, reports can be created from the data's current snapshot.
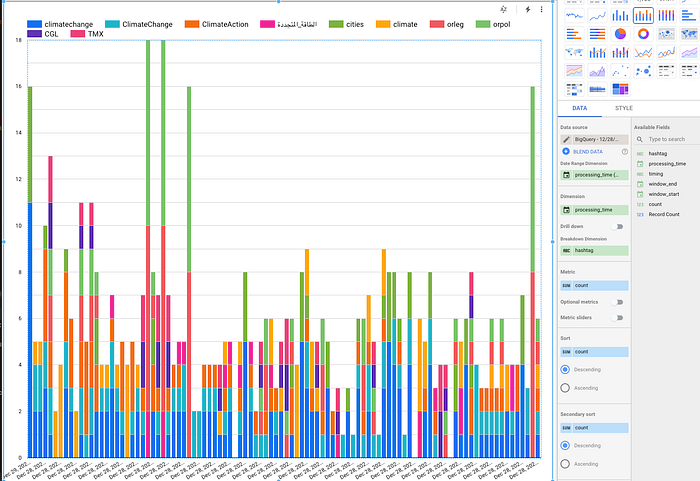
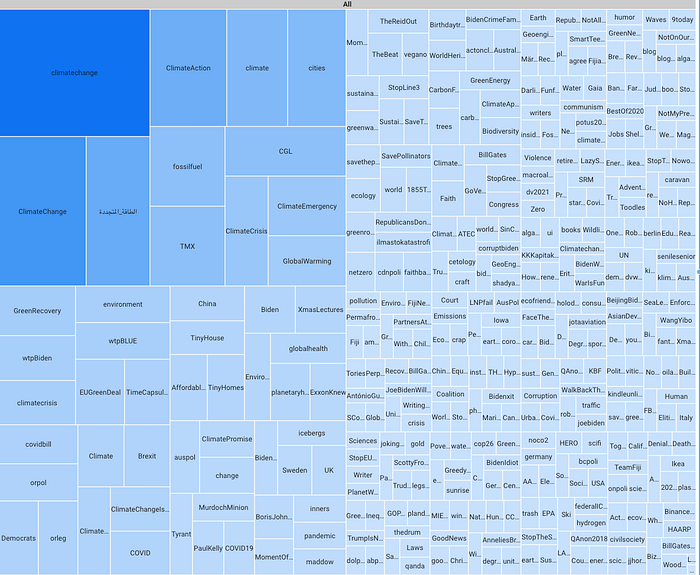
- Streamlit App: This is the real-time dashboard app that automatically loads the latest data from the GCS bucket. The windowed data to the bucket is written by the Beam app every 20sec.
Streamlit is a framework to visualize data with little code. The data preparation, UI chart components, and binding are declared in python code. Streamlit takes care of the rest. For this application, the Altair bar chart data frame is populated from the latest window data in the GCS bucket and refreshed periodically.
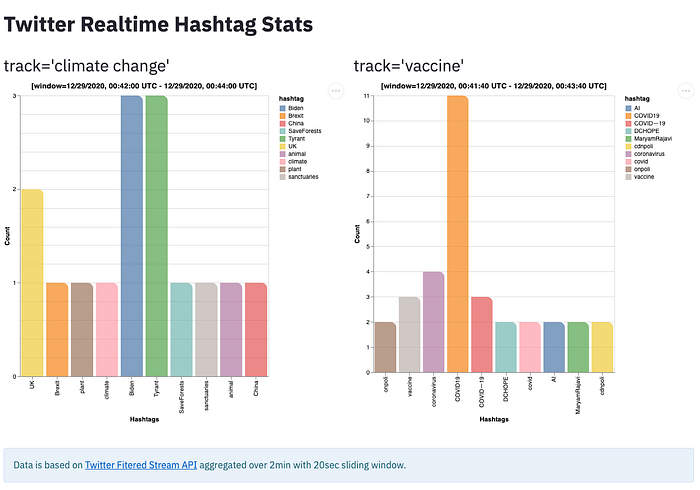
Below is the screenshot of the real-time dashboard app deployed to Google App Engine.
Footnotes
Prod Considerations
The app outlined in this article is an example illustrating powerful frameworks and tools to have a working real-time dashboard app quickly, focusing on processing logic and data generation. To make it production-ready, we need to address many factors.
- Deployment: Google App Engine maintains versions of the app and lets developers control the new version's promotion as detailed here. We canary rollout by disabling auto-promotion, splitting the traffic between new and old versions, and slowly increasing the exposure to the latest version.


- Scaling: Each data pipeline unit is per track query to Twitter API and independent of each other. With the auto-scaling abilities of Google App Engine and Dataflow, if there is an increase in the demand, the number of instances/workers will go up. Keeping each track on separate pipelines allow independent scaling but has the downside of depending on the control plane. A hybrid model can assign tracks to pipeline/topic/dataflow job instances based on the requirements.
- Data retention and lifecycle configuration: For this app, the GCS is configured to delete objects after 24h period. This approach might not be feasible for production cases; therefore, GCS folders can be partitioned by day to retain the data longer without impacting read performance.
- Logging, monitoring: When processing data at scale in production and displaying real-time, veracity is critical. Distributed tracing, anomaly detection, and alerts can help identify issues and fast recovery.
Recap
This article aimed to provide a high-level view of a real-time application using some of the best technologies available to developers. Please comment if you have questions, would like to see further details on any of the sections. We would love to hear your experience with end-to-end data applications, trade-offs you needed to make, and production learnings.
